




Using conventional listening, we listen through biased ears, hearing some fraction of what’s said. It’s our brain’s fault. I’ve developed a way to supersede our brain.
Most of us assume we accurately hear what others say. But it’s not even possible! There are several issues involved that impede accurate listening. I’ll take them one at a time. They’re manageable, but it’s quite important to realize we can’t hear accurately! It’s not because we don’t want to or because we’re not paying attention. Our brains just conspire against us.
- Words Our speech is basically a run-on sentence. That gives our brains a lot of work to do to figure out where one word stops and one starts. Babies take about a year to recognize demarcations between words; it’s only then they begin to speak.
- Memory In recent studies they’ve found that words are held in ST memory for 3 seconds. So it’s hard to retain what’s been said in the early part of a dialogue.
- Time Our social construct requires we speak within 200 ms after our CP finishes speaking. And It takes about 600 ms to formulate a response. That means we actually stop listening and begin formulating a response before a speaker is done speaking… and our brains sort of fill in the blanks according to our historic circuitry. Obviously we have no idea what we missed, although it’s safe to say we miss at least some of our CPs comments.
- Expectations: we often enter conversations with expectations and assumptions causing a restricted listening that also ignores some % of what was said, and our brain fills in the missing bits for us.
Here are some simple techniques to help mitigate these language problems:
- Announce to your communication partner that you will wait about 3 seconds after they’re done speaking to make sure you’ve heard their full dialogue, and please don’t be offended by the delay.
- During or after an exchange, say “I want to make sure I heard you correctly, so I’d like to repeat what I think I’ve heard. Please correct me where I’ve got it wrong.”
BRAINS
Now let’s take a look at what’s going on in our brains that also causes a listening problem.
Our brain processes 400 Billion bits of info per sec, is only aware of about 2,000 million of those & remembers about .5 million. There are 86 million neurons in our brains & 100 trillion neural connections. None of these processes involve meaning. It’s all electro chemical & unconscious. And because there is so much happening, the brain can only pay attention to a tiny percentage of what we experience – made worse by our confirmation biases & historic assumptions. Indeed, what we think we hear someone say is but some fraction of what they intend to share, even though we tend to believe what our brains tell us as accurate. Let me explain.
The book This is the Voice says that speech is a connected flow of ever-changing musical pitches determined by the rate of vibrations of the ‘phonating vocal chords’ filtered by the changing length and shape of the throat and mouth and lips interspersed with bursts of noises. There is no meaning involved! Let me explain:
All words, all sounds, enter our ears as puffs of air – vibrations. As such, they have no meaning. Similar to the way color enters our eyes as frequencies that then get translated into color by our rods and cones once it’s in our eyes. Basically everything we see or hear is an illusion, based on the way our brain translates the incoming vibrations.
Our brain then filters these vibrations against our mental models, values, and history, makes them into signals that get sent down existing superhighways of meaning, to understand what’s said in relation to what we’ve already got programmed and what we’re familiar with, regardless of the intent or meaning of the Speaker. In other words, we translate incoming words according to what matches our existing circuitry.
There’s a specific trajectory as speech or sound comes into our ears and we make meaning. I’ll take you through each element so you get a better understanding of how we end up hearing what we hear.
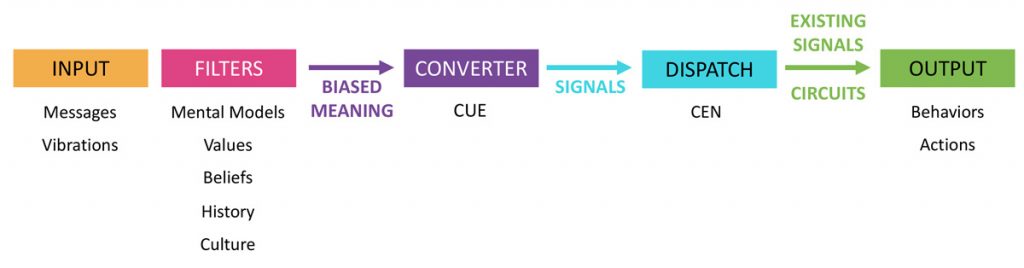
What we think we hear begins (INPUT) with someone speaking;
- puffs of air – incoming vibrations, sound waves – go immediately to our FILTERS to get sorted, categorized by
- our mental models (history, beliefs, experience, etc.) which sends them to
- a CUE that converts the identified vibrations into SIGNALS (So by the time the vibrations are signals, they already have meaning that represents our way of making sense of the world.) to
- the CEN, or Central Executive Network which seeks out existing circuits, neural pathways and synapses, that already exist and are ‘similar-enough’ to the incoming signals, for translation.
- The meaning or action is the OUTPUT, either what we think we hear or behaviors.
In other words, everything we think is told us is biased, since all signals are translated according to the meaning of the circuits we already have and obviously merely some % of accurate.
I recently had someone tell me I mistakenly put the hyphen in the wrong place in my name and meant to tell her my name was Drew-Morgen instead of Sharon-Drew.
So from puffs of air, to categorization filter, to signals, to a dispatch unit that finds similar enough circuits to translate into meaning or action. And it’s all still electro chemical, with no meaning at all until the output.
And believe it or not the story gets worse: where the signals don’t exactly match the circuits chosen, our brain either kindly deletes whatever doesn’t match, or it fills in the empty spaces with whatever it wants causing listeners to hear some variation of what was said. So if our communication partner says ABC we might hear ABL and adamantly believe we’re right because our brain actually told us ABL and omitted D, E, F, etc.
And this all occurs in 5 one hundredths of a second.
For those of us whose jobs depend on hearing/interpreting accurately – coaches, managers, leaders, doctors…well, everyone! – it’s pretty difficult, using our natural listening process. But we certainly need to make sure we get as accurate an interpretation as possible. I’ve written extensively on this, with an entire chapter on ways to help accurate hearing in What? Did you really say what I think I heard?
For those seeking to train their teams or just learn how to hear with as little bias as possible, go to the application section. Or contact me: sharondrew@sharondrewmorgen.com